


FileMaker 作るメディア管理DBの話。メタデータを取得して専用メタテーブルに展開して利用します。ExifTool を利用します。
ExifTool の取得と利用 – 概要と前提
以前、FileMakerでメディア管理 – メタデータの取得で、取得をレベルに分けました。
LEVEL 1 何もしない
LEVEL 2 GetAsText
LEVEL 3 GetContainerAttribute
LEVEL 4 AppleScript
LEVEL 5 Exiftool
今回は LEVEL 5 ExifTool を使用してでメタデータを取得するお話です。
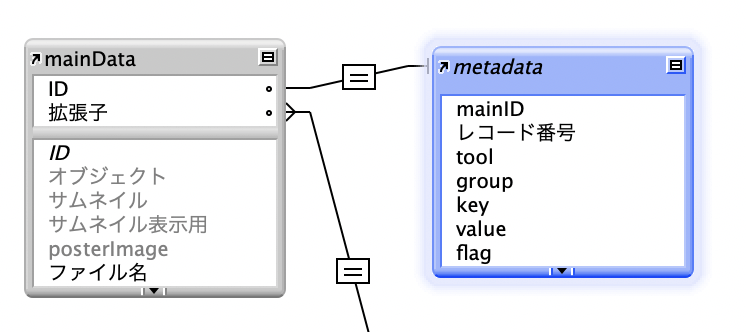
前提として、メインのテーブルがすでにあってメディア管理が成り立っている状態です。IDがあり、オブジェクトフィールドがあります。また、別にメタデータのテーブルがあり、IDでリレーションされていて、タグ名と値のフィールドを持っている、つまり FileMakerで作るメディア管理データベースの存在が前提ということで、このポストはFileMakerメディア管理 R12 Exiftool と連動しています。
ExifTool をインストール
ExifTool はメタデータの取得や編集ができるコマンドラインで使うツールです。公式サイトにインストーラーを用意してくださっているので、ダウンロードしてインストールします → exiftool.org
ExifTool のちょっと詳しい話は ExifToolのかんたんなメモ をご覧ください。
取得と利用
何を取得し、どう利用するか。ここでは、個別にタグを指定せず全てのメタデータを取得し、FileMaker のメタテーブルにレコード化します。メインテーブルとIDで繋がったメタテーブルにグループ、タグ名、値を網羅します。このテーブルをメインテーブルにポータル表示し、小技を駆使して利用価値を高めます。

取得するターゲットは、ファイル一つだけの場合もあればフォルダを指定してその中身のファイル全部の場合もあります。通常はメディア管理にインポートする際に同時にメタデータを取得することが多いでしょう。
以前はフォルダ指定とファイル単体でコマンドを分けていましたが、その必要もなく基本的に同じ exiftool コマンドとオプションを使用します。むしろフォルダ指定で「サブフォルダを含めるか含めないか」で若干オプションを使い分けます。
埋め込み
メタデータの書き込み、埋め込みと言ったほうがいいのか、これは、一つのファイルにメタデータを埋め込みます。メタデータの編集とも言えます。また、これはエクスポートと密接です。ExifTool を使ってファイルにメタデータを埋め込むこと自体は容易なので、どちらかというとFileMakerでどう処理するかが難易度ポイントとなるでしょう。
CodeRun の前提
ExifTool はコマンドラインで命じるツールで、普通はターミナルにたたたっとタイプして使います。ここでは、FileMaker 書類の内部から直接命じることを前提とします。これは、CodeManager というコード管理&実行システムの CodeRun を使います。なんのこっちゃと今思いましたね。当然ですね。これに関しては次の記事を参照してください。
→ Macで実行可能なFileMakerコード管理 CodeManager v2
ExifTool のコマンドやオプションに触れても、実行のさせ方についてはここでは触れませんのでその前提でお願いします。
ExifTool でメタデータを取得
取得のざっくり工程
ざっくり工程はこうです。最初に ExifTool のコマンドにオプションを付け足してコードを完成させ実行、メタデータをだーっと取得します。このとき取得する形式は JSON です。取得する内容は指定したフォルダ以下にあるメタデータの束の全ファイル分の束です。
全ファイル分の束の束(タバタバ)をゲットしたら、次にこれをファイル単位の束(タンタバ)に分割し、各レコードのフィールドに納めます。これを歌で言うと ゲットタバタバ、タンタバ分配。と、こうなります。
タンタバ分配によって各レコードにメタデータの束が納められました。次に各レコードの束をメタデータ各項目に分割し、メタデータ格納テーブルにレコード化します。これを歌で例えると「タンタバ分割メタデタ分配」と、なります。続けて歌うとこうなります。
ゲットタバタバ、タンタバ分配、タンタバ分割メタデタ分配
いえ、馬鹿な歌を歌う必要はありません。
ゲット ExifTool タバタバ
まずは CodeRun で実行させるゲットタバタバ ExifTool のコード作りからです。
必要な情報はターゲットのフォルダまたはファイルのパスです。もうひとつ、フォルダの場合サブフォルダを含めるか含めないかの選択ですが、この選択は事前にインポートの設定で決定済みとします。
CodeRun にコードを作るので、変数を含むテンプレ的な書き方で完成させ、実行時に実際の値と置き換えます。
ExifTool を使った基本のコードはこうしています。
exiftool -j -api largefilesupport=1 <OPTION> -s -g -d '%Y/%m/%d %H:%M:%S' <PATH>
最後の <PATH> は、ここに目的パスが入ります。パスはファイルでもフォルダでもOK。フォルダの場合、最後に / を付けないでね。
<OPTION> は、「 -r 」が入るかまたは空欄です。-r が入ると「サブフォルダを含む」になります。このオプションも <PATH> 同様、実際の使用時に置き換えます。
他のオプションについて軽く解説しておきます。
-j
JSON 形式で出力させます。JSON を使う理由は、ただいちびっているからではありません。普通にゲットすると、拡張子のないファイルでエラーになるからです。JSON で受け取るのが安全です。
訳註: いちびる = 調子に乗る、格好を付ける
-api largefilesupport=1
でかいファイルをサポートするオプションです。ムービーファイルでは必須です。ムービーファイル以外では意味ないかもしれませんが付けっぱなしにしておきます。
-s, -g
-s は短いタグ名、-g はグループの取得です。-s はわざわざ付けなくていいのかな。わからないけど付けてます。グループも取得して利用します。
-d ‘%Y/%m/%d %H:%M:%S’
取得する日付のフォーマット。2022/08/22 0:30:45 という形で取得します。
以上、基本の ExifTool スクリプトでした。が、これで完成ではありません。このスクリプトで得られた結果を出力し、それを受け取って処理しなければなりません。出力を設定しましょう。
| pbcopy
筆者大好きコマンドの pbcopy、結果をクリップボードに収めます。これを使いたいところですが、今回は使用しません。ファイル数が多いとき、受け取る結果が長大なテキスト量になるのでコピーでは無理しすぎてヤバい感じになるからです。ここは素直にテキストファイルに書き出しましょう。
> 書き出し先パス
これを付け足します。
exiftool -j -api largefilesupport=1 <OPTION> -s -g -d '%Y/%m/%d %H:%M:%S' <PATH> > <PATH2>
ということで書き出し先パス PATH2 をあらかじめ作っておかなければなりません。書き出し先はどこでもいいのですが、よくあるのはFileMakerのテンポラリフォルダです。姿も見えないしFileMaker終了時に消えて無くなりますし、パスの指定も簡単で悩まずに済みます。
Get ( テンポラリパス ) & json.txt
こんな感じで。これで結果がテンポラリフォルダ内のjson.txtに書き出されました。テスト中はあえてデスクトップなど見える場所に作って内容を確認しながら作業するのがよろしいでしょう。
FileMaker スクリプト GetJSON to File
以上を FileMaker のスクリプトで組み立てていきます。ここでは CodeRun の説明を割愛しているし、書き出したファイルから読み込む一連の流れも割愛しているのでスカスカですが一応流れだけ。
1 CodeRun(事前にコード設定済み) 各パラメータを記入( codeID, POSIX1, POSIX2, OPSION )して実行
2 結果を「結果フィールド」に読み込む
以上です。
次に、書き出されたテキストを読み込んで処理します。
ExifTool が書き出したテキストファイルを読み込む
pbcopy だと結果を受け取るのが簡単ですが、テキストファイルに書き出したので面倒なことになりました。FileMakerでこれを読み込まなければなりません。
FileMaker 18 以降でしたっけ、データファイルを扱えるようになりました。とっても難しいんですが超便利でもあります。ファイルを処理するには、次の処理をきっちり行います。
閉じ忘れに注意です。あと、謎のデータファイルID、やや理解が難しいですが「勝手に作られ勝手に指定変数に入る特定一意のID」と認識しておけば大丈夫です。
FileMakerヘルプの「データファイルから読み取る」に書かれた例3を参考に、読み取るスクリプトを作成し、最終的に「結果フィールド」へ格納されるように仕向けました。
ゲットしたタバタバ(JSON)をタンタバに分割してレコードに分配
はい、そんなわけで JSON 形式の結果が結果フィールドに収まりました。ここには、メタデータの束がファイル数の分だけ束になった束の束タバタバが格納されています。もし指定がファイル単体なら束が何個入っているか数えると「1」であるというだけです。
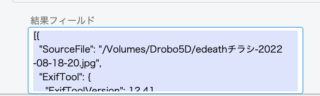
結果フィールドの JSON データを今からどうにかしなければなりません。難易度高いです。計算式やスクリプトで乗り切りましょう。
はじまりの JSON
まずタバタバJSONをレコードタンタバに分割するわけですが、出力されたJSONに特徴がありますのでそれを元に関数を組み立ててスクリプトを作っていきます。
タバタバは全体が [ ] で括られ、その中に { } が入っています。{ } が、ファイル毎のタンタバです。ざっくり書くとこうなっています。
[ { } { } { } ]
こういう形になっていて、ファイルタンタバである { } が束になって入っています。ファイル単体からゲットしたのなら [ { } ] と、一個だけ入っています。
さて、コンピュータの世界に限らず、大体宇宙のすべては key と value で出来ています。JSON も同じです。”ImageSize”: “1000×600″ なら、”ImageSize” が key、”1000×600″ がvalue(値)です。
ところが最初に出てくる最上位の配列 [ { } { } { } ] には key がなく、value { } だけが並んでいるように見えます。これがタバタバの特徴で、実は見えないだけで key はあります。それは連番です。key がない最初の配列には 0 から始まる連番がkeyとして振られています。
JSONListKeys()
FileMaker の JSON 関数にはkeyのリストを取り出す関数があります。
JSONListKeys ( JSON ; "" )
と、keyまたはパス指定を “” とすることでトップ階層のkeyリスト即ち見えない連番をゲットできます。この関数の結果は0から始まる数字の改行リストになります。
もし3個のファイルならこう、
0 1 2
ファイル単体からゲットしたJSONなら「 0 」と1行返されます。
では FileMaker のスクリプトを組み立てましょう。
FileMaker スクリプト JSONをレコードに分配
Get JSON to File の結果をレコードに分配するスクリプトです。その前に。
これまで黙っていましたが「レコードに分配」というとき、どのテーブルのレコードに分配するのかという条件があります。
インポートの作業の中では、ImportJSON というテーブルにレコード化します。ImportJSONにレコード分配した後、Import テーブルに合流させます。インポートの終わりに、メインデータのテーブルに転記します。
通常のブラウズ中では、Import テーブルにレコード化します。レコード化が済んでから、メインデータテーブルに転記します。
いずれにせよ、メインデータテーブルを直接指定せず、必ず作業用 Import テーブルを介します。では行きます。
1 対象となるテーブルのフィールド名を変数に作っておく($JSON_field、$posix_field、$パスモドキ_field)… 詳細は割愛。
2 トップ階層 “” の key リスト(連番)をゲット(タバタバJSONを $$JSON に保存しています)
変数を設定 [ $topKeyList ; 値: JSONListKeys ( $$JSON ; "" ) ]
3 $topKeyList の行数を $vc に、カウンタ $c = 1 をセット。ついでにトップのkeyが0から始まる連番だと判っているから手抜きして $key = 0 もセットしておきます。
変数を設定 [ $vc ; 値: ValueCount ( $topKeyList ) ] 変数を設定 [ $c ; 値: 1 ] 変数を設定 [ $key ; 値: 0 ]
3 ループを開始します。
レコードタンタバのJSONには、”SourceFile” という key が必ずあり、ファイルパスが格納されています。これを取り出しておくのが重要ポイントになります。パスを取得したらパスモドキも作っておきます。
Loop
# key で GetElement してレコードのJSONを取得
変数を設定 [ $json ; 値: JSONGetElement ( $$JSON ; $key ) ]
# "Source" をゲット
変数を設定 [ $posix ; 値: JSONGetElement ( $JSON ; "SourceFile" ) ]
変数を設定 [ $パスモドキ ; 値: Right ( $posix ; 100 ) ]
タンタバ $json とその中身の一部であるパスを手に入れたのでレコード化します(レコードを作るテーブルのレイアウトにいる前提です)
新規レコード/検索条件
フィールドを名前で設定 [ $json_field ; $json ]
フィールドを名前で設定 [ $posix_field ; $posix ]
フィールドを名前で設定 [ $パスモドキ_field ; $パスモドキ ]
変数を設定 [ $c ; 値: $c + 1 ]
変数を設定 [ $key ; 値: $key + 1 ]
Exit Loop if [ $c > $vc ]
end Loop
4 この後、パスモドキリレーションにより Import, ImportJSON, mainData が繋がりますので状況に応じた転記を行って完了です。
タバタバJSON をファイルタンタバに分割しただけなので簡単な処理になりました。この後、各レコードに出向いて、レコードのタンタバをメタデータ一個ずつに分割します。
この時点で、タンタバからその内容をゲットして分割して分配することを同時に行うこともできます。できますが、Loop地獄に陥るのでそれを避けました。スクリプトを細かく作っておくことも大切です。
$$JSON
Loop
処理1:$$JSON からファイル単位の $json を取り出す
Loop
処理2:$json から グループ $group を取り出す
Loop
処理3:$group から メタデータ $key と $value を取り出す($value にもたまに階層がある)
Loop
処理4;$value から key と value を取り出す
新規レコード
end Loop
end Loop
end Loop
end Loop
こんな風になりまして、混乱の元です。スクリプトを分けましょう。ということで、最初にJSON全体をゲット、次に全体JSONをファイルごとに分割しました。次は、ファイルのjsonをメタデータに分割します。
レコードのJSONをメタデータに分割してレコードに分配
ここからはレコードごとの処理です。上記のループ地獄なら処理時間も短縮できそうですが、敢えて分けています。レコード毎の処理なら、処理するレコード数を調整できるし、処理するタイミングも任意に決められるからです。
ちょっと話が実作ファイル MediaDB の事情になりますが、インポートスクリプトでは上記「ファイル毎のJSONをレコードのjsonフィールドに格納する」までを区切りとしています。ここから先はインポートの続きでやるもよし、後で時間があるときにやるも良しという形にしています。
ということで、メインテーブルのレコードにはファイルのJSONがフィールドに格納されました。このJSONを分割して、別のメタデータテーブルにレコード化します。
JSONの形
最初のJSONでは [ { } { } { } { } ] のように全体が [ ] で括られていました。ここから取り出したファイル毎のJSON は全体が { } 波括弧で括られます。ExifTool でグループを取得していますから形としては入れ子になってます。
{
"グループ名": {
"key": "value",
"key": "value",
"key": "value"
},
"グループ名": {
"key": "value",
"key": "value",
"key": "value"
}
}
たまに value の中が配列になっていてさらに “value”: { “key” : “value”,”key” : “value” }となっている場合もあります。でも今のところこれを無視しています💦
FileMaker スクリプト ファイルJSONをメタデータに分配
レコードJSONをメタデータテーブルに分割・分配するスクリプトは次のよう流れです。
# 変数各種 $$recJSON(レコードのJSON), $$ID(レコードのID), $tool(これは"ExifTool"と) # 処理1 $$recJSON から グループ名のリスト $gList を作成 変数を設定 [ $gList ; 値: JSONListKeys ( $$recJSON ; "" ) ] # Loop用変数 $vc(行数) $c(カウンタ) Loop $c = $c +1 exit loop if ( $c > $vc ) # 処理2:$JSON からグループ $group を取り出す 変数を設定 [ $groupName ; 値: GetValue ( $gList ; $c ) ] 変数を設定 [ $groupJSON ; 値: JSONGetElement ( $$recJSON ; $groupName ) ] # グループ内のkeyリスト 変数を設定 [ $tagList ; 値: JSONListKeys ( $groupJSON ; "" )] ここで"SourceFile" の例外処理あり(このkeyを無視する分岐) # tagList をループする準備 $vc2(行数) $c2(カウンタ) Loop $c2 = $c2 +1 exit loop if ( $c2 > $vc2 ) 処理2:$group から メタデータ $key と $value を取り出す($value にもたまに階層があるが無視) (ここに最初だけ $group と $$ID のみを記入する新規レコードの処理) 新規レコード idフィールドに $$ID groupフィールドに $group key フィールドに $key value フィールドに $value tool フィールドに $tool ここで metaKeys の処理 end Loop end Loop
“SourceFile”を無視する処理を加えています。というのも、グループ名と並列に SourceFile がありまして、これはグループ名ではなく key です。ループ処理ではグループ名を元にグループ内Loopを入れてるのでエラーになるんですよね。面倒な記述から逃げ、SourceFileを無視する分岐だけ設けてごまかしました。もともとSourceFileはパスを生成するのに使用していて用も済んでるからこれでいいのだ。
もう一つ。「最初だけ Group のみ」というレコードを作っています。これは本質とあまり関係がなく、メタデータのテーブルをメインレイアウトでポータル表示するための工夫です。ポータルでグループ名をタイトルに折り畳みを実現するのに使います。
さらにもう一つ。「metaKey処理」が挟まっていますが、これ何かというと、メタデータのいくつか特定一意の key をメインデータ内のフィールドに昇格させる処理です。これについては後述します。
という事情を挟みつつ、レコードのJSONをメタデータテーブルに分配するスクリプトでした。
![]() 取得の話が長くなってしまいましたが、こうしてレコードと繋がったメタテーブルに ExifTool でゲットしたタグと値のリストが作られました。
取得の話が長くなってしまいましたが、こうしてレコードと繋がったメタテーブルに ExifTool でゲットしたタグと値のリストが作られました。
結果を利用
さて、ExifTool のコマンドを実行させた結果を FileMaker で利用します。それって例えばどういうことですか。こういうことです。
そのまま閲覧する
メタテーブルにデータが網羅されますから、ポータル表示などを使って閲覧します。
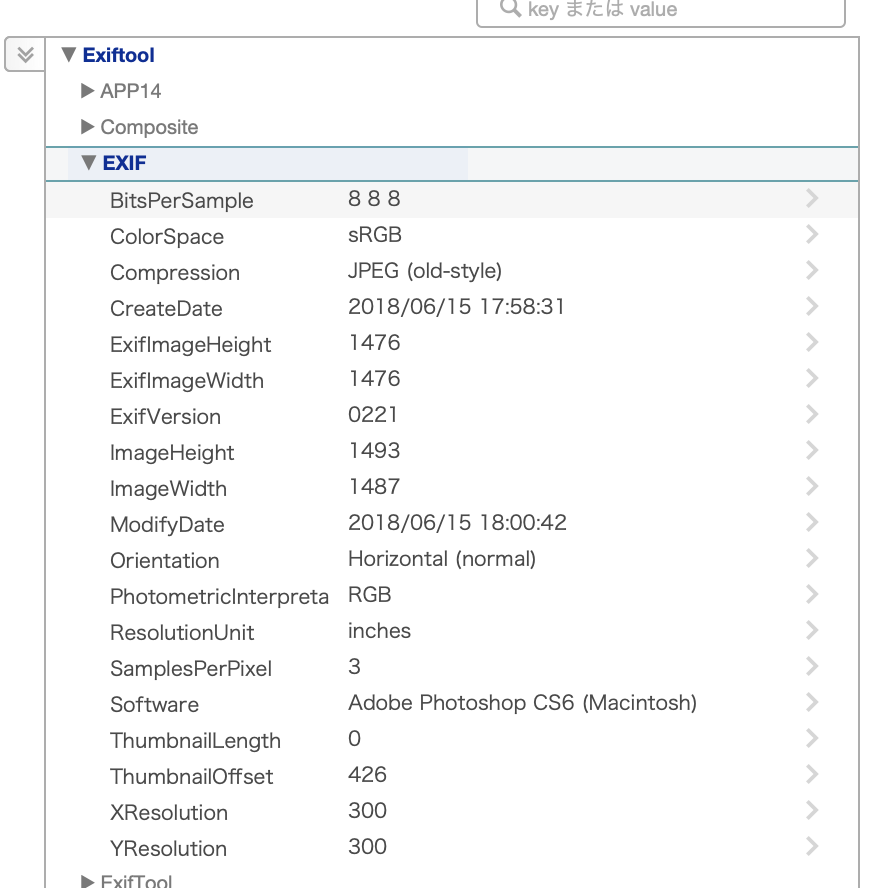
この知恵と工夫のポータル表示では、タイトルの折り畳みが可能です。
編集する
もしかしたらタグの値を編集したいことがあるかもしれません。編集してはいけない・できないタグも多くありますが。これは、メタテーブルの編集であって、実際のファイルのメタデータを変更する行為ではありません。データベース上でのみでの変更です。
Tips
タグの値を編集したら、編集したことを記録させましょう。実作編 v5 では、更新スタンプとmeta_logというフィールドに記録し、見た目も変更させます。
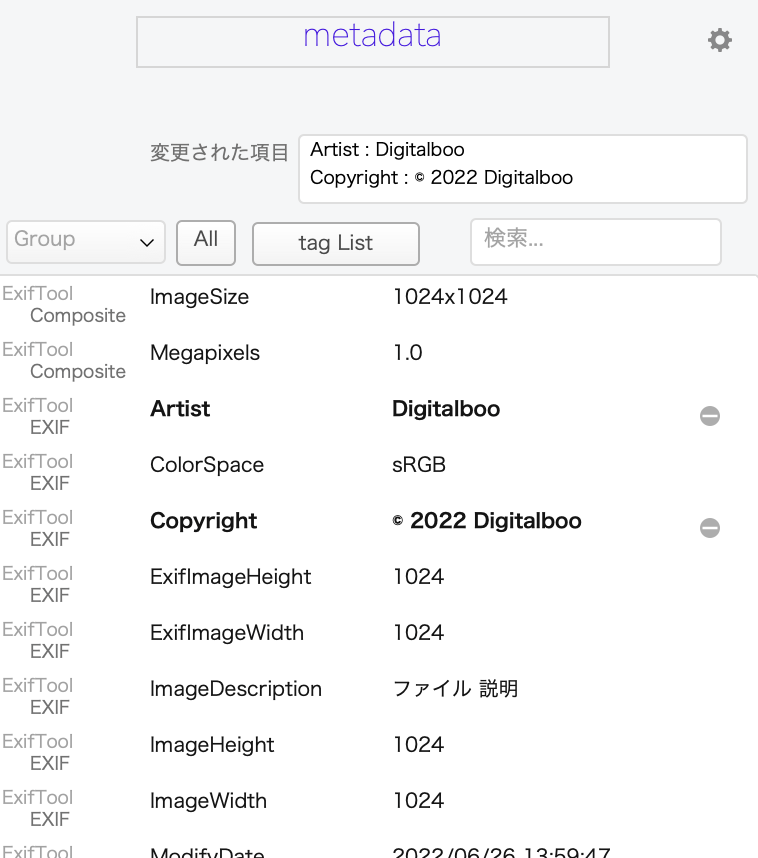
※ この機能は、連載終了した実作編v5で採用していました。今はどこにも使われておりません。記録として残していますが、タグの編集については新シリーズでいずれ別の形で登場するかもしれません。
フィールドに昇格
先の「取得」の中で触れた特定タグをフィールドに昇格させる件です。
レコードのフィールドとして特定一意のタグを昇格させます。例えば「DateTimeCreated」を「オリジナル作成日」フィールドに転記したり「MIMEType」を「MIMEType」フィールドに転記したりします。そんな必要があるのか。たまにあります。レコードが検索しやすくなったりソートのネタにできたりその他取り扱い的に有利になるからです。
フィールドに昇格させる方法
メタテーブルのレコードにある特定タグの値を、メインテーブルの特定フィールドに上手く転記する良い方法あるでしょうか。
良いかどうかわかりませんが、こうしました。タグ名を網羅したデータベースファイルを新たにこしらえてメタテーブルとリレーション、このファイルにはentry_fieldというメインデータのフィールド名を同じ値を持つフィールドがあります。タグ名リレーションにてフィールド名と同じフィールドがあれば値を転記するという仕組みです。
フィールドに昇格させるために取ったこの方法が、Exif データをファイルに書き込む際にも役に立ちました。章を新たにしてご説明。
ExifToolTags metaKeys テーブル
ExifToolでメタデータをゲットしてメタテーブルに網羅したわけですが、ある特定のタグに対して特別な措置を施したいことがあります。そういうとき、普通はタグ名を検索して絞り込んて処理したりします。でもそれってマジ面倒。融通も利かなくなるし。他の方法を探ります。
タグ名のカタログを作れば良い
タグ名カタログを作ればいいんじゃないかと思って、それを作りました。タグ名メインのテーブル、その名も ExifToolTags テーブルです。
※このテーブルは後にファイルとなりました。現在ではmetaKeysという名前でDBToolsの一角を担っています。
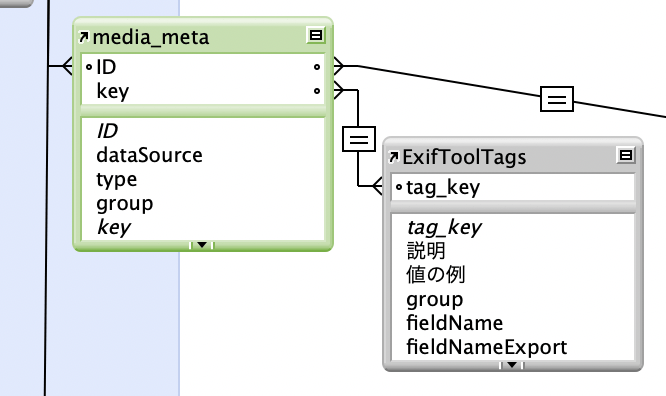
メタデータのテーブルはすでにありますから、それを利用してまずはだーっと転記してタグ名カタログを完成させます。「値の例」なんかも転記しておくと便利。何なら「説明」フィールド作って説明をメモっておいたりします。
このテーブルはExifToolでゲット出来るタグのカタログと化します。metaテーブルに合わせて未登録タグがあれば自動で増えていく仕組みもつくりました。これだけでも結構使えるデータベースではないでしょうか。
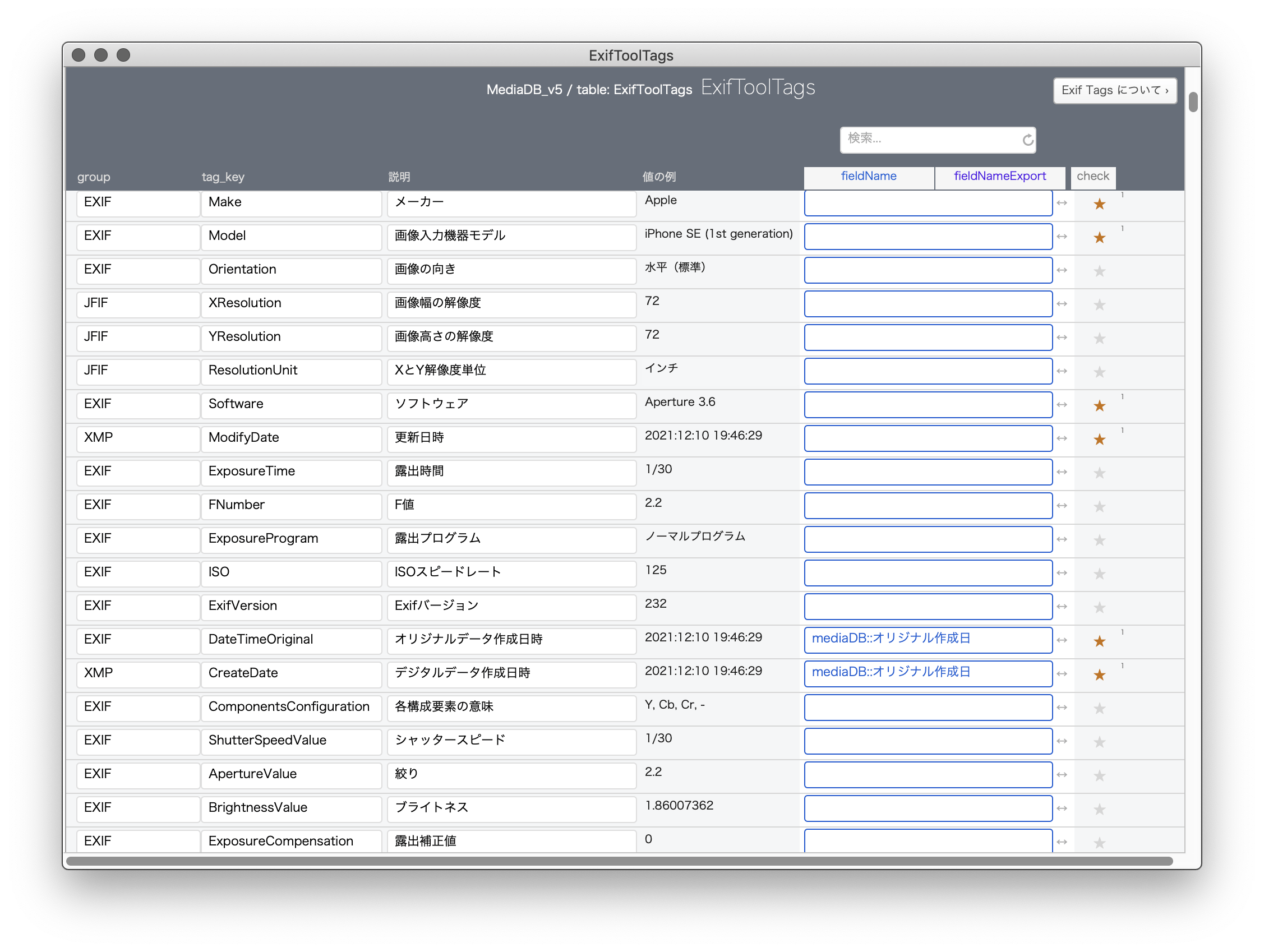
さてお立ち会い。このタグカタログにさらにフィールドを付け足します。「FieldName」後の「entry_field」フィールドです。名前なんてどうでもよろしい。それで、何ですかそれは。それはフィールド名を記すためのフィールドです。図で見ての通り、特定タグの fieldName フィールドには、何やらフルフィールド名が記されていますね。こうしておくことで、メインテーブルのフィールドとタグ名が密接な間柄になります。
メタデータをゲットするスクリプトのループの中で、タグ名と共に fieldName が存在していることを確認すれば、そのフィールドに値を転記することができます。
同じように、別途「fieldNameExport」というフィールドもこしらえまして、こちらはメタデータを埋め込むときに特定タグのみを指定することに利用できます。
メタデータを埋め込む
ExifTool オプション
-タグ名=
メタデータを埋め込むには、-タグ名= で値を書きます。コピーライトを埋め込むには、-Copyright=’© 2022 Digitalboo’ のように書けばいいですね。そのタグが既存にあれば上書き、なければ追加されます。コピーライトタグを消したいときは -Copyright= と、値を書かずにおきます。
-overwrite_original_in_place
もうひとつ良いオプションがあります。-overwrite_original_in_place です。これは、強制的上書きするのですが、基本のところを変更しないようにするオプションです。-overwrite_original では、ファイル変更日などがすべて変わってしまいますがそれを防げます。
IPTC の対処
大事な話がひとつありました。ExifTool で編集、追加は容易に出来ますが、言葉の壁によってダダハマりして大層苦労しました。Keywords など、一部のタグがどうしても文字化けするんです。苦労話は聞きたくないでしょうからすっ飛ばしますが、答えは、そのタグが IPTC タグであったからでした。IPTC は、素のままでは UTF=8 のキャラクタを認識できないのでした。特別にオプションを足します。それはこうです。
-iptc:all -codedcharacterset=utf8
ということで、それらを踏まえてターミナルでたたたっとやれば簡単ですが、これをメディアDBとどのように関連づけて操作体系を作るかです。
これが最高のやりかたやで。と、自信たっぷりには何も言えません。苦肉の策で現状どうやっているかだけ軽くご説明します。
CodeRun
簡単に言うと、CodeRun を操作します。CodeRun は特定のコードをテンプレ的に使用する仕組みですが、ちょっと特殊な使い方として、そのテンプレそのものを作り変えてしまいます。
CodeRun の基本のテンプレコードはこうしておきます。
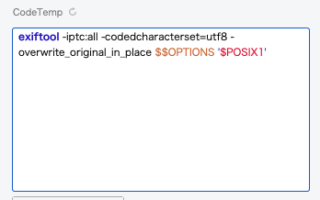
この基本のテンプレコードの中に、編集したいタグを付け加えていきます。そういうスクリプトを作っておきます。はて。編集したいタグとは。それはレコード上で編集したタグです。
ということで、まずはメタテーブル上で変更されたタグを抽出します。これは meta_log フィールドを頼りに実現できます。他に、フィールドのいくつかがメタデータと関連づけられていますから、そのフィールドに変更があれば、そのタグも抽出します。
管理DBで変更があったタグをこうして抽出し、リスト化した後、工夫して CodeRun に書き込み、実行させます。
例えば、著作権絡みのメタデータを軒並み編集した後にスクリプトを発動するとこのようになります。
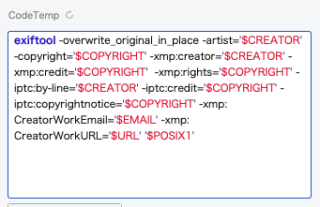
あとは CoddRun するだけで埋め込めますね。
なんという雑な説明。これは CodeRun について熟知していないとわけわからんですね。でも説明しだすとたいへんなので。すいません。実作編V5をダウンロードして、その中のCodeRun テーブルやスクリプトを直接覗いてみてください。

以上、メタデータの取得と利用 LEVEL 5 ExifTool 編をお送りしました。一部過去の内容がそのまま残っていて現在のMediaDBと合わない話もありますがご了承ください。








